
Best Way to Build an AI Engine in 2026
%20copy.jpg)
What’s the best way to build an AI engine in 2026?
Start by choosing your LLM provider: OpenAI and Anthropic are the leading options. Layer on a framework suited to your stack: PydanticAI for Python backends, Vercel AI SDK for full-stack TypeScript. Add agentic search over your data and production observability from day one. Specific choices matter less than your ability to swap them as the landscape shifts. Build for adaptability, not just capability. Start with evals, pick your stack, ship, and iterate.
It’s 2026 and every SaaS needs an AI engine now more than ever. We’ve written in detail about AI engines before, but it is time to have a fresh look on available techologies to build an AI Engine. An AI Engine is a critical piece of software that is responsible for processing data and running algorithms and machine learning models, including LLMs and AI agents, to achieve business goals.
AI engines are highly tailored for each business, since every one has access to different data sources, needs their own data analyses, has custom reporting responsibilities and in general strives for unique outcomes.
Based on our experience in building several AI-native SaaS solutions and helping our industrial clients implement AI in their workflows, here are our recommendations and comparisons between alternatives for building the best AI engine in 2026.
LLM provider comparison
The core of an agentic AI engine is of course an LLM. Here the critical decisions are: do you need to fine-tune or retrain LLMs, or is context engineering enough to get the job done? Do you need local inference, or are 3rd party cloud solutions accepted?
In 99% of AI solutions, context engineering indeed is necessary and sufficient. Fine-tuning is a whole new infrastructure and software solution that needs to be designed, implemented and mastered by the team. If investing in fine-tuning, prepare for several iterations and continuous monitoring for your training data, accuracy benchmarks and deployment performance.
For commercial providers, capabilities from top providers (OpenAI, Anthropic, Google) have pretty much converged, with Opus 4.5 being the current king. Deploying Opus 4.5 to production remains rare due to the cost vs performance ratio: the level of intelligence is not actually needed in most solutions and the cost quickly ramps up.
Anyway, it is almost pointless to write statements about current best models as the race to ship better and better LLMs is so hot that yesterday’s news don’t matter. Let’s turn our comparison back to the bigger picture, e.g. model providers.
We favor Azure as our LLM provider, since we get a great selection of models (OpenAI and Anthropic as well as open source ones like Llama models). Importantly, we can control deployment regions and get excellent privacy and data security guarantees. Just be mindful of quotas on the consumption plan with regional deployments in Azure, they are surprisingly low for use cases that are scaling up user count.
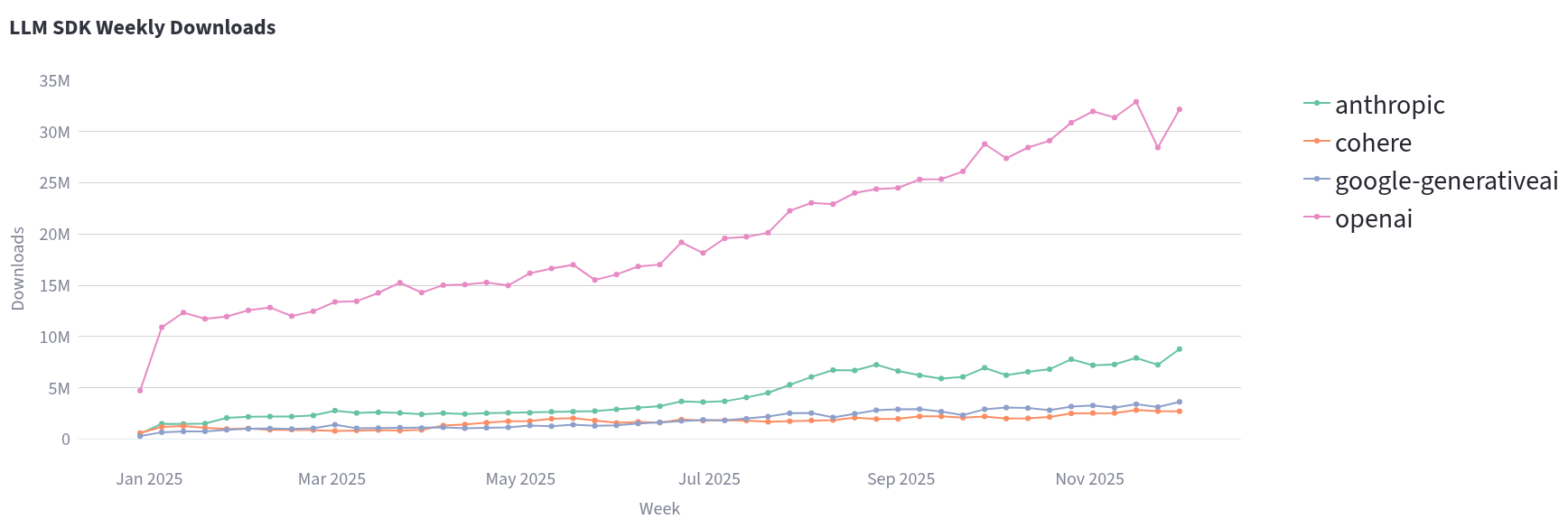
To look at overall popularity, we can have a look at downloads for Python SDKs of different providers. This (and the following Python data) is based on PyPi downloads, visualized with the excellent ClickPy by ClickHouse. Note that download numbers are useful for rough analysis only, as they can be gamed and affected in multiple ways. The numbers include CI/CD pipeline installs, bots, mirrors, and automated dependency updates, which means actual developer usage is lower than raw downloads suggest. A single company might generate thousands of downloads through their build pipelines while only having a handful of developers actually using the package. Additionally, package managers cache dependencies, so some real installations don’t show up in the stats at all. Despite these limitations, download metrics remain a good proxy for framework adoption.
In the numbers, OpenAI SDK dominates, but Anthropic is on the rise.
Best transcription and voice services
Transcription is essential for analyzing audio and video data with machine learning models like LLMs, by converting spoken language into text. Key features of a transcription system include timestamping, diarization (speaker segmentation), multi-language support, real-time capability, and PII redaction. Fast/real-time transcription often trades quality and features for speed compared to batch services.
For batch transcription, the primary choices are AWS Transcribe and Azure AI Speech Whisper, each with distinct trade-offs:
- AWS Transcribe: Generally faster and highly accurate on a single-word level, but at a higher cost. Recommended as the starting point for batch work.
- Azure AI Speech Whisper: Tends to be slower but utilizes the Whisper model for a polished, state-of-the-art result, and is significantly more cost-effective. A good backup if output quality is a concern or for cost optimization at high volumes.
For streaming and single-request needs, the service quality is more consistent across providers, with options available from AWS and Azure.
OpenAI still has the current leading real-time conversational model.
In all transcription applications, validating PII redaction both on the service side and application side is recommended.
Best AI vision services in 2026
Vision services provide image understanding capabilities, ranging from recognizing text (OCR) and object detection to generic image description. They power diverse applications from document processing to scene understanding. Capabilities are often accessed via cloud APIs (e.g., Google Vision, AWS Rekognition, Azure Computer Vision, OpenAI / Bedrock API) or self-hosted deep-learning solutions (e.g., YOLO, Segment Anything).
While pretrained models handle general tasks well, domain-specific visual content often requires fine-tuned or custom-trained models, with fine-tuning offering significant performance upgrades in vision tasks. Modern multimodal LLMs are good for content description but are error prone for precise tasks like counting or pixel-level outlining. Therefore, the best vision capabilities are achieved by combining multimodal LLMs with classic vision models.
Compute & PaaS comparison
When you do deploy open LLMs, generative AI models or traditional machine learning models, you want to look for compute and infrastructure providers that give on-demand GPU or TPU access.
Our preference for deploying to GPUs is Modal. The developer experience is great, pricing is reasonable and the technology works really well. It’s possible to use AWS or Azure for GPU work loads, but the whole process feels outdated, after you get a taste of modern cloud providers like Modal or Railway.
Speaking of Railway - they really have the feel of a modern cloud with great UX. Features are not AWS or Azure level for building enterprise software, but for many SaaS applications and independent services it truly shines. The Railway MCP and CLI pair well with tools like Claude Code and Codex when vibe co.. developing with AI assistance!
Railway is not a GPU provider though, so keep that in mind.
Search and retrieval infrastructure
Let’s face it, semantic search has been dethroned. As LLM capabilities have improved, especially in context size and tool calling complexity, semantic search is no longer the default option for search infrastructure that it used to be.
Semantic search is many times still useful, but almost never sufficient alone. Especially with massive data sets, semantic search in high dimensional vector spaces loses accuracy. Then you’re faced with the typical decision to make: how to keep your semantic index in sync with ground truth data, what embedding models to use, best vector distance metrics.. All decisions that depend on the business domain.
Agentic search is our go to pattern. How to implement agentic search? Give your AI agent free roam on your source data so that it achieves high recall, then filter to obtain accurate search results. More good news: the infrastructure needs are a bit simpler than in semantic search. Keyword search capabilities are needed and they are readily available for critical business data, often in SQL databases or internal wikis, or via search engines.
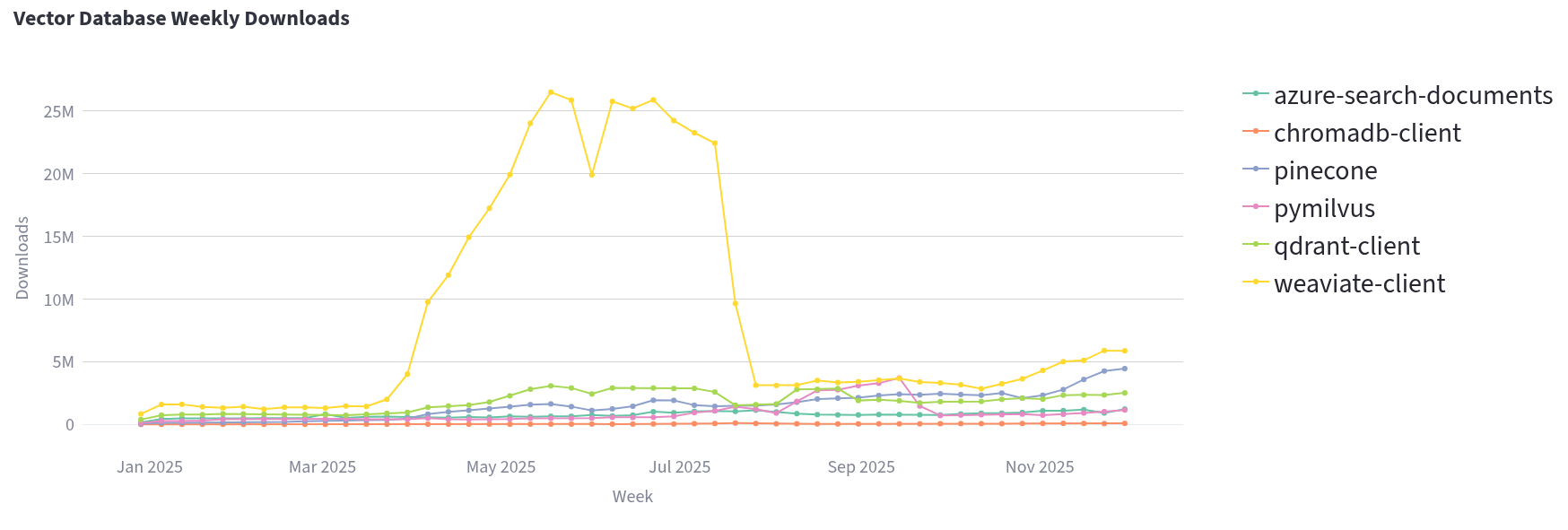
On to the recommendations! Pgvector for Postgres is one to watch and has become a go-to option for small projects. It is improving in performance at a rapid rate, and the convenience of having a single database for all data is just sweet.
With very high-dimensional vectors or massive data sets, you may want to look at dedicated vector search software, but be sure to run your own benchmarks when making performance-critical choices. We love Qdrant for vector and hybrid search. Great performance, great UX, truly open source. In fact we’re contributors. Azure AI Search is our runner up and makes sense for businesses already invested in the Microsoft stack as it has useful integrations to speed up your delivery times.
Filtering, e.g. reranking, is essential in all search implementations. It requires very little infrastructure in basic format. For reranking, all you really need is an LLM, no need to invest in separate technologies unless it becomes a bottleneck.
What is the most popular vector database, or semantic search infrastructure provider? Let’s have a look at Python SDK downloads again.
Frameworks and libraries
When choosing AI frameworks for AI engines, use cases must drive the choice. Tools like LlamaIndex shine for off-the-shelf RAG solutions and agentic patterns, but sometimes you just want to build with lower level primitives.
Concrete rule of thumb:
- Use a RAG / Agent framework when you want fast iteration, standard RAG building blocks, and common agent patterns out of the box.
- Use primitives when you need novel agentic logic, deep performance tuning or strict governance.
By primitives we mean frameworks like Vercel’s AI SDK, PydanticAI or LangGraph. It’s rarely necessary to use LLM provider APIs directly in new software. That abstraction has been handled for you in several open-source libraries. Here, frameworks that we mostly use are PydanticAI and Vercel AI SDK.
Vercel’s full-stack framework just really lets us ship a lot faster and they nailed the abstraction very well. The interfaces are clean and if needed we have control of almost everything, be it agentic workflows or LLM parameters and tool calling. Paired with the AI Elements for building agentic UI’s, it makes for a great toolkit.
We just built a novel agentic AI search solution for our client in the media sector on top of Vercel’s AI SDK and exceeded all expectations in both scope and timeline of the project. It’s that nice.
For pure backend AI projects I’d still go Python and PydanticAI, at least if any other data work is required with LLMs. It pairs extremely well with Logfire (see tracing and monitoring), but note that Logfire works with other frameworks as well. And in Python you get FastAPI, which is unmatched.
Let’s look at the popularity of Python AI frameworks. These include tools for building RAG pipelines, copilots, agents, support bots… essentially the full circus. We find that LangChain dominates the numbers. It makes sense, they had the early mover advantage. The journey has been interesting to watch as well. Early adapters remember LangChain as the framework that made magic happen with poor GPT models. As LangChain grew rapidly, it accumulated some code quality criticism from the open source community. But what is now the LangChain core is essentially a rewrite and a step up in quality. Moreover, LangGraph is a very solid tool with good abstractions for developing reliable agentic workflows. It is raising in popularity quickly as well.
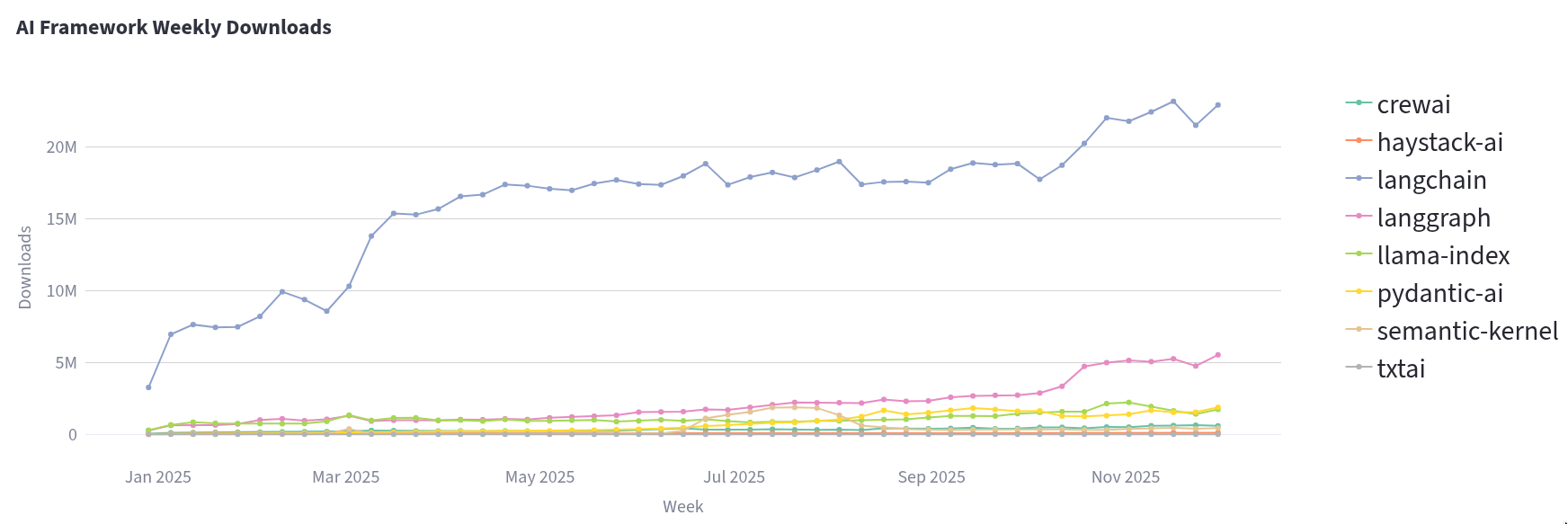
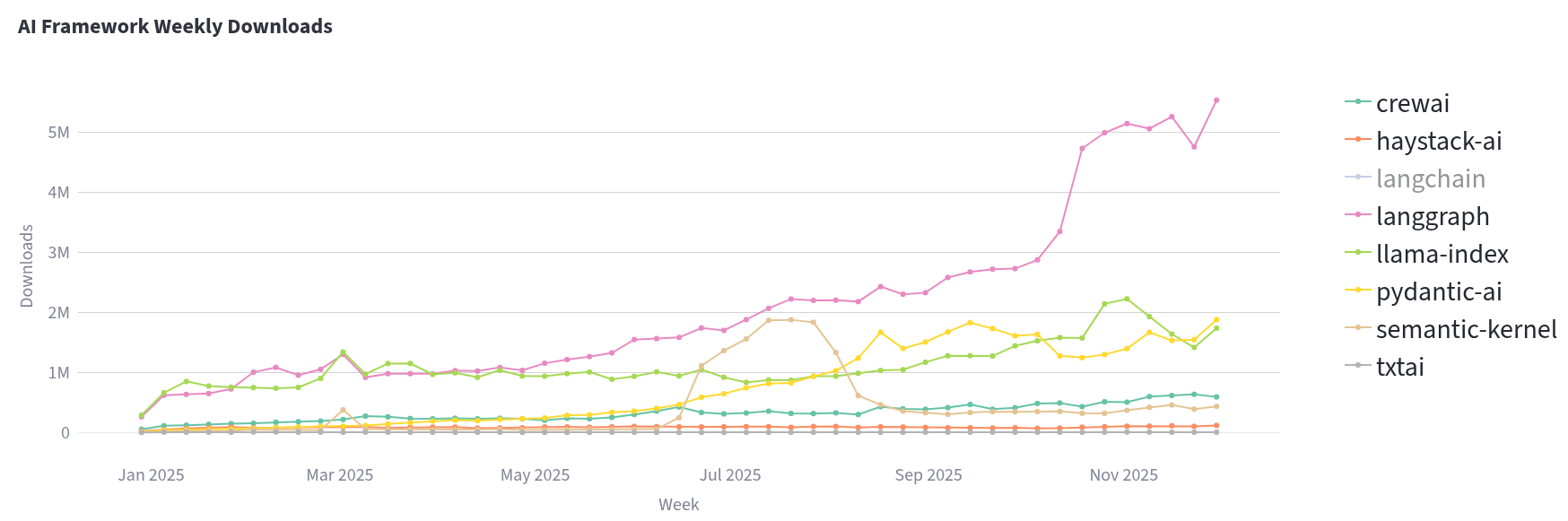
PydanticAI is rising in popularity for a good reason and LlamaIndex is a stable for anyone looking to connect their data with LLMs. We purposefully included the stats only for provided-agnostic libraries here. OpenAI has their own Agents SDK for example, which is great if you are rolling your own abstraction over it or committed to OpenAI for the lifetime of your software. Not necessarily a bad choice, but we like to keep our options open.
So there, we build primarily in Python and TypeScript. If you’re curious about Applied AI in Rust, check our EuroRust session on on-prem Rust-powered LLM inference.
Truth be told, most SaaS projects require more infrastructure, cloud and integration expertise than cutting edge RAG methods or agentic cascades. Here is a prioritized list of requirements for you, the frameworks you use should support these:
- Integration to existing technologies
- Security, privacy, governance, authx
- Maintainability and testability
- Developer experience and speed of iteration (especially with AI-assisted development)
- Reliability
- Observability and LLM evals
- Cost
- Runtime expectations
Our choices above facilitate careful consideration of the above requirements.
For the core machine learning work, outside of GenAI, the primary tools remain Pytorch, Scikit-Learn and XGBoost.
Tracing and monitoring
Observability is non-negotiable for production AI systems. LLM performance can be irregular and costs vary per model and use case, sometimes unexpectedly. Tools like Logfire (our favourite) offer deep visibility into agentic workflows, helping to debug, optimize and monitor everything that goes in an AI engine. Since Logfire supports the Open Telemetry format, it can actually ingest much more than just LLM traces, offering a great total observability and monitoring solution, including dashboards and queries into the collected data.
There are many Logfire alternatives, including classic monitoring solutions Prometheus or LLM specific solutions like Langfuse. None quite match the UX of Logfire, but do provider better options on the open-source and self-hosting side. So if that is a requirement.
Evals
Promptfoo is our favourite for running eval sets across providers and scoring LLM answers over different types of metrics from deterministic to LLM-as-a-judge evals. It’s just simple to use and we can share results with clients easily.
For state-of-the-art LLM judges for nuanced and domain specific evals, we turn to Root Signals.
Note that evals are not a substitute for unit tests, and it’s even possible to implement evals as unit tests if that suits your workflow better.
But with evals, technology is almost secondary.
The most important thing with evals is to get started now. You need visibility into LLM performance in order to make educated decisions about models and implementation patterns. The jagged frontier of LLMs keeps delivering surprises and the only way to ensure quality is to embrace the irregular (even non-deterministic) behavior and get some numbers to drive decision making.
I would also like to highlight that looking at LLM benchmarks is not a substitute for running your own evals! It’s easy to game the numbers, and suffice to say that the real-world performance of GPT-5.2 or Gemini 3 has not actually lived up to the expectations that benchmarks were showing. Your team deploys LLM to execute a specific function, and the only way to know how well LLMs are doing is to evaluate them on domain specific data and metrics.
To get started with evals, this is what you need:
- Eval cases, e.g. input and expected output pairs in your business domain
- Metrics: what makes a good response and how to measure that
- Ownership: a person who makes it their priority to check that deployed AI agents and LLMs are doing well on your evals
- LLMs: to generate answer and to score answers
Practical recommendations on technology selection for your AI engine
These technology choices share one thing: they let you iterate quickly. Modal deploys in minutes, not days. Vercel AI SDK lets you swap providers without rewriting your codebase. Logfire shows you what’s actually happening in production so you can fix issues before they become incidents.
The AI landscape changes every quarter. GPT-5.2 underperformed its benchmarks. Opus 4.5 became the new standard. Your advantage isn’t picking the perfect model today, it’s building infrastructure that lets you adapt when the next one ships.
Start with evals. They’re the foundation that makes everything else measurable. Pick your LLM provider and monitoring solution. Ship something. Then use your eval numbers to drive the next decision.
The best AI engine in 2026 is the one you can improve next month.


name

Jerry Liu
CEO & Co-founder

Shreya Rajpal
CEO and Co-founder

Zander Matheson
CEO & Co-founder
Andre Zayarni
CEO & Co-founder